For me, training neural networks has always seemed prohibitively expensive. To train one to produce compelling results must take a very long time with very expensive computers, right?
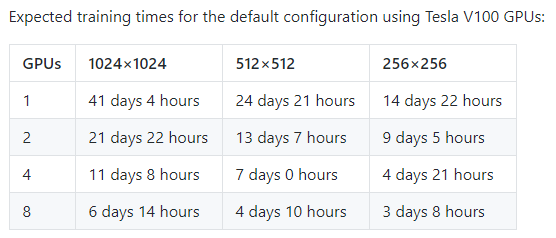
If you take a look at the StyleGAN, you might think that. Like most projects pushing the state of art, Nvidia is using the latest and greatest enterprise GPUs to produce their models, and on high resolution images like their faces dataset, they indicate that it would take 41 days of GPU time to train such a model, on a card that most people have limited access to. Their documentation also mentions needing 12GB of GPU RAM – more than most folks have lying around!
But is that the reality?
Thanks to some more informed folks on Twitter, I decided to go ahead and try to train a model on my own and see how much it really costs to get plausible seeming results – and found that it is much less demanding than I might have otherwise expected.
Training at Home
The first revelation to me was that you don’t need to have a fancy GPU to train these models. The V100 that Nvidia used may be important when you’re training with a cluster of 8 GPUs – or, like Uber apparently does, with a cluster of 128 GPUs – but these high end enterprise targeted models do not make an order of magnitude difference.
There are two big things that make a difference with having a much higher end graphics card: First, the amount of memory it has. There is absolutely the possibility that if you don’t have a high end graphics card, you may not be able to train a network around 1024x1024px images that are used for the Flickr faces model that StyleGAN produced, and a lower amount of RAM may impact your ability to train as quickly.
The second difference is simply the ability to use these cards in a large cluster. But if you’re looking to just train something for “fun”, you don’t need a massive cluster of GPUs – you wouldn’t want to pay for one anyway! And even if you did have it: scaling on training these models is consistently sub-linear. Adding more GPUs may make the task take less wall time, but it doesn’t make it take less GPU time.
With this information available, and some suggestions that training a model that would start producing outputs could be done in less than a day, I set about setting up my home computer to train a model.
StyleGAN is apparently different from previous models in part because it trains by starting with lower resolution data. So as your training progresses, primarily what you are doing is producing images that look plausible at higher and higher resolutions. This has two effects: The very early training can move pretty quickly, and it also produces something that can “look right” when zoomed out pretty quickly.
Using a single GTX 1080 consumer grade graphics card, within 4 hours, I had images coming out that looked melty, but were clearly recognizable as taking the shape of rooms.

At 10 hours in, those rooms had started to take shape, and the average person would probably guess they were kitchens (rather than say, bedrooms or living rooms).

After 25 hours, the result was images that still look goofy, but would probably pass a quick visual skim most of the time as a low resolution thumbnail on a house listing.

Each additional layer of resolution added to the images slows down the training process. As you add more data, the training process slows, gaining incremental improvements on previous models. However, contrary to my expectation, it was not only straightforward, it was not at all time consuming to produce a model that was producing interesting output (if still not anything that would fool a real person).
Training in the Cloud
Of course, 24 hours is a long time. And I’m an impatient man. I see benchmarks from Nvidia showing that the V100 is extremely powerful! It even has a thing called Tensor Cores, clearly this is the way to go, since I’m using tensorflow!
Turns out… maybe not so much.
The V100 is an extremely powerful graphics card. I do not in any way dispute that for some workloads, it may provide a massive improvement in speed over a consumer graphics card. But for training StyleGAN, that’s not the reality that I experienced.
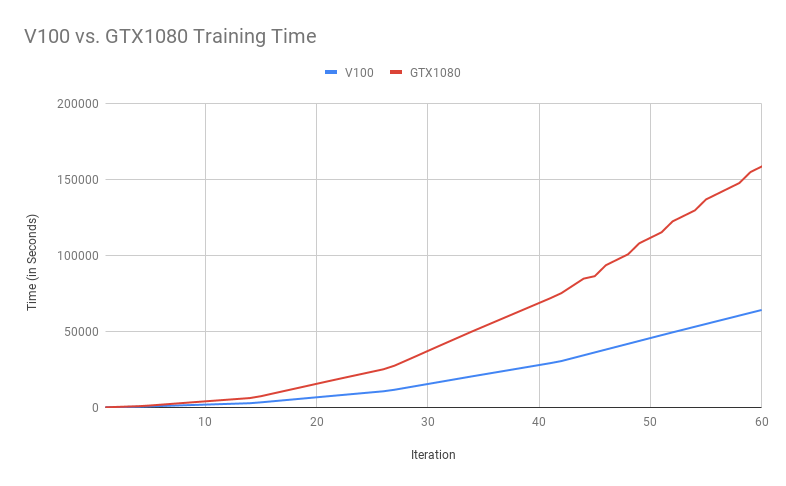
(Total training time at each iteration of model training: lower is better. The V100 is consistently about 2.5x faster than the GTX1080.)
At lower resolutions, the V100 trains at about twice the speed of the GTX1080 card; at higher resolutions this climbs to about a 2.5x improvement, and is steady from there. To complete 60 iterations of the StyleGAN training on a single V100 required just under 18 hours of GPU time, while on the GTX 1080, it required 44 hours.
I don’t mean to indicate that the V100 is not a faster card: it absolutely is. I just have to admit that I was disappointed to find out that my initial expectations were off: Given that there’s something like a factor of twenty difference in price between the V100 and the GTX1080, I was naively hoping I might get at least a 10x improvement in speed.
Since the relative rate has stayed pretty stable over the past ~12 hours of training, I feel pretty good in thinking that there isn’t likely to be a point in the curve where the V100 takes off.
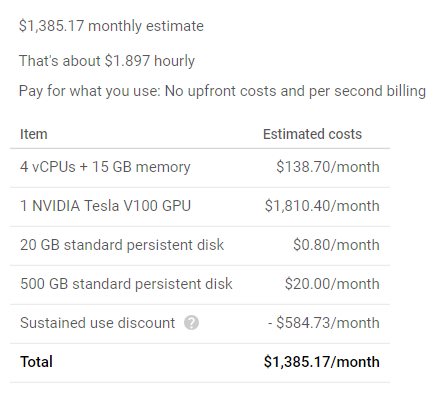
The nice thing about the cloud is that you can convert time spent directly to costs. The ongoing question for many models is “How difficult is it for someone else to reproduce this result?” This gives a sense of how much effort it would take for a bad actor to replicate results like those that are presented. Using a single V100 GPU would have a cost of about $2.60/hour, or $1.90/hour after monthly discounts, if you use it that long.
So, with that in mind, I can simply price out how much it would cost to get to a point where I could take any large image set and produce plausible looking low resolution sample data that matches it.

(You can also look at the full res image.)
{kind=link}
After 18 hours of training, this is the result: a set of images that look pretty plausible when looked at at low resolution. $50 will buy you enough compute to build a model which can produce an effectively unlimited number of images just like this: For less than the cost of the After 18 hours of training, this is the result: a set of images that look pretty plausible when looked at at low resolution. $50 will buy you enough compute to build a model which can produce an effectively unlimited number of images just like this: For less than the cost of the latest Super Smash Brothers, you too can have your own infinite living room generator!
Speed and Cost Comparison
Of course, there are a whole lot of different GPUs available for you to use. Google Cloud, for example, offers K80, P100, and V100 GPUs (as well as some more specialized options like the P4 / T4 cards). How do these cards stack up, in price per performance?
To estimate the difference, I used the same training data, and compared training 20 iterations of the StyleGAN model on each of the K80, P100, dual P100s, and single V100.
I compare each of these to the baseline of the V100 in performance and price per performance.
| Performance | GPU Price/Hour | Price/Performance Ratio | |
|---|---|---|---|
| V100 | 1x | $2.48 | 248 |
| 2x P100 | 1.19x | $2.92 | 347 |
| P100 | 1.79x | $1.46 | 267 |
| GTX 1080 | 2.29x | n/a | n/a |
| K80 | 5.4x | $0.45 | 243 |
Overall, we see that for single-GPU performance, the cost is actually pretty stable. Using the arbitrary scaling above (computed via performance rating divided by inverse of GPU price/hour), we see that the K80 is an odd outlier – using just the GPU price, it seems like it would actually be the cheapest option to run this particular workload (assuming you had no limit on time).
However, this leaves out an important consideration: the base instance – separate from the GPU – still does have a cost. In my testing, I used an n1-standard-4 VM, with 4 virtual CPUs and 15GB of RAM, at a US cost of 19 cents/hour.
| Performance | GPU + Instance Price/Hour | Price/Performance Ratio | |
|---|---|---|---|
| V100 | 1x | $2.67 | 267 |
| 2x P100 | 1.19x | $3.11 | 370 |
| P100 | 1.79x | $1.65 | 295 |
| GTX 1080 | 2.29x | n/a | n/a |
| K80 | 5.4x | 0.68 | 367 |
This changes the equation significantly, making it clear that the V100 is by far the most cost effective option for training a StyleGAN model in Google Cloud.
Disclaimer: I work for Google, but do not work on Google Cloud or any related product; I just happened to have more experience with these tools. This is not an endorsement of Google, and my opinions are my own and not those of my employer.
In Nvidia’s GitHub repo, they indicated training time improvements for using multiple V100 GPUs that were substantial. On training a 256px x 256px model like I am training, their results indicated that the model should train about 60% faster with a second GPU. That was consistent with the results I got on training after 20 iterations: a 60% higher ratio of performance by adding the second card. Unfortunately, since the price scales linearly, that 60% higher performance is a significant loser in the total cost department – even more so than the K80. (Admittedly, the dual P100 does train almost 5x faster than the single K80, so it’s clear that there are potential wins besides the cost.)
Still, even with two P100 cards, the performance of the V100 could not be topped, despite a 17% difference in cost, with the V100 being lower cost.
The GTX1080 on these same metrics has a performance factor that puts it in the same ballpark as a single P100 – with the benefit that running it si substantially lower cost, even with pricy New England electricity.
Of course, finding the fastest GPU isn’t going to save you a lot if you’re wasting a bunch of time training stuff that you don’t need to. So for that, the real trick is to not train from scratch, but let someone else do the hard work: use transfer learning.